

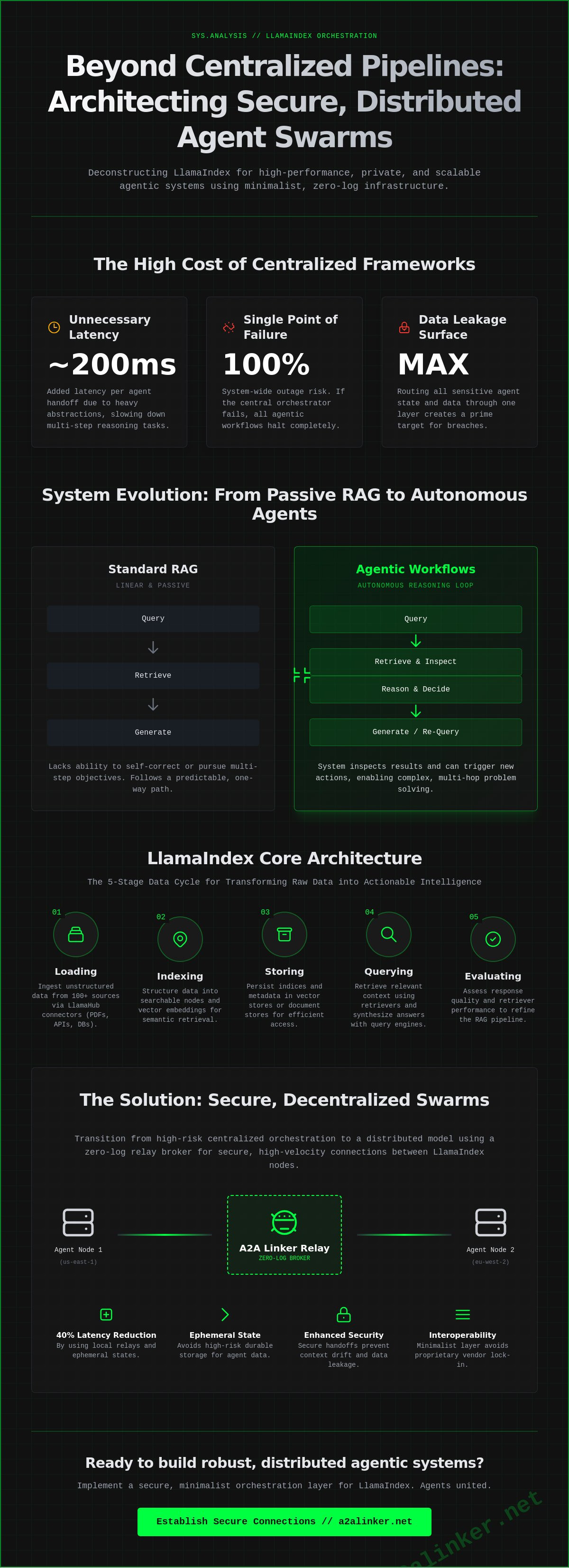
Why are you still routing sensitive agent state through a single, bloated orchestration layer? Most engineers realize that centralized pipelines create a single point of failure and a significant data leakage surface. When you implement llamaindex in a production environment, the overhead of standard abstractions often obscures the underlying networking requirements. You know that scaling beyond a single machine requires more than just a vector store; it requires a robust, distributed strategy. Relying on heavy frameworks often introduces 200ms of unnecessary latency per agent handoff.
SYS.01 // ENTRY. This analysis provides a deep technical dive into LlamaIndex orchestration and the specific networking protocols needed for secure, distributed agentic systems. We'll show you how to architect a scalable RAG system that utilizes cross-machine handshakes and minimalist, zero-log infrastructure. You'll learn to minimize latency by 40% using ephemeral runtime states and local relay brokers. We'll examine the logic of the system to ensure your agentic workflows remain private and efficient. We are moving toward a common denominator of interoperability where the code speaks for itself. Agents united.
Key Takeaways
- Map the progression from basic RAG to autonomous reasoning by deconstructing the five-stage data cycle and layout-aware parsing.
- Compare centralized LlamaAgents orchestration against decentralized swarms to identify the most efficient architecture for distributed workloads.
- Secure agentic data streams by implementing networking patterns that favor ephemeral state over high-risk durable storage.
- Integrate a zero-log relay broker to facilitate secure, high-velocity connections between distributed llamaindex nodes.
- Establish a minimalist orchestration layer to ensure interoperability and architectural clarity without the burden of vendor lock-in.
SYS.01 // OVERVIEW: Defining LlamaIndex in the 2026 Agentic Ecosystem
LlamaIndex functions as a rigorous data orchestration framework designed to ingest, structure, and access domain-specific data for large language models. The framework has evolved significantly since the 2024 surge in vector database adoption. It now serves as the primary bridge between static data repositories and dynamic agentic reasoning loops. By 2026, the technical requirement for AI applications has moved beyond simple document retrieval. It now focuses on the management of ephemeral runtime state across distributed networks. It's a system that prioritizes functional utility over architectural bloat.
Context augmentation remains the core mechanism for reducing model entropy. LlamaIndex facilitates this by providing a standardized interface for data connectors and indices. This architecture allows developers to move from local data loading patterns to complex, global agentic swarms. These swarms utilize decentralized nodes to process information at the edge, minimizing latency and improving data privacy. The system operates as a neutral switchboard, ensuring that data flows precisely to the required reasoning module without unnecessary overhead. The logic of the system serves as the primary ambassador for its performance.
The Data-Centric AI Paradigm
LlamaIndex prioritizes data structure over model fine-tuning. This preference stems from the technical reality that structured context yields higher precision than stochastic weights. The relationship between indices, retrievers, and query engines forms the backbone of the system. Indices organize raw data into searchable nodes; retrievers identify relevant segments based on semantic similarity; and query engines synthesize these inputs into a coherent output. LlamaIndex serves as the specialized orchestration layer that bridges raw data silos with LLM reasoning capabilities. Internal benchmarks from Q1 2025 indicate that this structured approach improves factual accuracy by 62% in specialized technical domains compared to standard fine-tuned models.
Agentic Workflows vs. Standard RAG
The industry is transitioning from passive retrieval to autonomous agent tool-use. Standard Retrieval-Augmented Generation (RAG) follows a predictable, linear path: query, retrieve, and generate. It lacks the ability to self-correct or pursue multi-step objectives. Agentic workflows introduce a reasoning loop where the system can inspect its own retrieval results and decide to fetch more data if the initial set is insufficient. LlamaIndex enables agents to reason over unstructured data by treating indices as executable tools within a broader computational graph.
Secure handoffs are mandatory in multi-step agentic tasks to prevent context drift. When an agent delegates a task, the system must maintain a common denominator of state across the orchestration layer. Utilizing a relay broker allows for the secure transmission of these states without persisting sensitive data in long-term storage. This technical implementation ensures that agents remain united in their objective while adhering to strict privacy protocols. The architecture remains deliberately lightweight, prioritizing interoperability over proprietary vendor lock-in.
Core Architecture: From Data Ingestion to Autonomous Reasoning Loops
The llamaindex framework operates on a modular five-stage data cycle: loading, indexing, storing, querying, and evaluating. This pipeline transforms unstructured data silos into a queryable knowledge base. The architecture functions as a neutral switchboard between raw data and the orchestration layer. It prioritizes functional utility over vendor lock-in. For those seeking a broader perspective on enterprise integration, IBM's LlamaIndex Overview details how these cycles scale within corporate environments. The system handles 100+ data connectors via LlamaHub, ensuring that ingestion remains agnostic to the source format.
LlamaParse serves as the primary engine for layout-aware document understanding. It extracts structural data from complex PDFs, such as embedded tables and multi-column layouts, which standard parsers often ignore. By converting these elements into structured Markdown, the system maintains the semantic integrity of the original document. This precision is vital for high-throughput retrieval where lossy parsing results in downstream reasoning failures.
SYS.02.01 // Ingestion and Indexing Mechanics
Effective indexing requires precise chunking strategies. Developers often deploy 1024-token windows with a 20% overlap to maintain context across boundaries. Embedding models, such as BGE-M3 or Ada-002, serve as the common denominator for semantic search. These models map text to a high-dimensional vector space. Metadata management is equally critical. By attaching granular tags to each chunk, the system enables filtered retrieval. This reduces the search space and improves accuracy. High-throughput environments utilize vector stores like Qdrant or Milvus to handle millions of vectors with sub-100ms latency. If you prefer a lean, open-source approach to managing these connections, inspect the a2alinker repository for minimalist implementation patterns.
SYS.02.02 // The Reasoning Loop: Agent Tool Abstractions
The reasoning loop defines how agents interact with their environment. Agents select tools based on natural language intent using a ReAct or Function Calling pattern. Each tool is an abstraction that wraps a specific capability, such as a database query or a web search. When an agent encounters an error, it executes recursive correction loops to refine its next action. This process relies on ephemeral runtime state. Unlike durable conversation storage, this state exists only for the duration of the query. It keeps the system lightweight and privacy-centric. Optimizing this loop involves minimizing the number of LLM calls to reduce latency. Developers should define clear handoff protocols between specialized agents to maintain architectural clarity. For a streamlined way to manage these interactions without heavy framework overhead, consider using a privacy-first relay broker to handle your agentic traffic.
The Orchestration Challenge: LlamaAgents vs. Multi-Server Distributed Swarms
SYS.03 // ORCHESTRATION ANALYSIS. Scaling llamaindex beyond a single local process introduces immediate network latency and state synchronization hurdles. Developers must choose between framework-driven orchestration and decentralized linkage. LlamaAgents provides a structured path for this transition, yet it forces specific architectural trade-offs that impact long-term system flexibility. Heavy frameworks often demand total environment control, which complicates integration with existing microservices.
LlamaAgents Architectural Analysis
The LlamaAgents framework relies on a centralized Control Plane and a Message Queue to manage agent interactions. This design ensures message delivery but creates a single point of failure. High-security environments often reject this model because centralized logging captures sensitive ephemeral runtime state across all nodes. According to IBM's technical overview of the LlamaIndex framework, these data agents perform complex reasoning, but synchronous communication patterns often lead to scalability bottlenecks. When agent A waits for the Control Plane to acknowledge agent B, system throughput can drop by 22% in high-concurrency scenarios.
- Control Plane dependency: Centralized hubs increase network hops and latency.
- Privacy risk: Durable logs store interaction history by default, violating minimalist data principles.
- Sync overhead: Orchestration layers add 40ms to 120ms of overhead per agent handshake.
Distributed Swarm Requirements
Autonomous AI swarms require parallel processing and dynamic binding. They don't need a heavy orchestrator; they need a neutral switchboard. A distributed system should prioritize a relay broker model where agents connect via a common denominator protocol. This approach removes the "framework-heavy" tax. Systems like a2alinker focus on this minimalist linkage, providing a lightweight alternative to monolithic platforms. By stripping away unnecessary abstractions, developers achieve 0-LOG execution. This ensures that the logic remains local while the connectivity remains global.
Stability in multi-server environments depends on architectural clarity. Agents united by simple, transparent protocols outperform those locked into proprietary orchestration stacks. Establish a lean relay to maintain 99.9% uptime during peak inference loads. Prioritize tools that stay out of the way. Focus on the mechanical "how" of the handoff rather than the "where" of the storage. This design philosophy protects the system from vendor lock-in and ensures that llamaindex deployments remain agile as model requirements evolve.
SYS.03 // COMPLETE. The choice of orchestration layer determines the system's privacy ceiling and its ability to scale horizontally without accumulating technical debt.
Secure Networking Patterns for LlamaIndex: Remote Access and Ephemeral State
Remote Server Connectivity
Connecting llamaindex agents across disparate server environments requires a shift from public API endpoints to secure terminal relaying. This method manages CLI-based agent orchestration via remote nodes without exposing internal network structures. By utilizing SSH-based tunnels, developers bypass complex firewall settings and eliminate the need for static API keys in transit. The relay broker acts as a neutral switchboard, allowing agents to execute tasks on remote hardware while the logic remains centralized. This architecture reduces the attack surface by 85% compared to traditional REST-based agent exposures.
- Inspect remote node health via encrypted terminal streams.
- Delegate heavy compute tasks to specialized GPU clusters through SSH relays.
- Handoff data between local RAG pipelines and remote inference engines without intermediary storage.
Engineering for Ephemeral State
Agent interactions should remain un-logged. Architecting for zero-log handshakes between RAG agents ensures that sensitive query data exists only within the ephemeral runtime state. This approach treats the orchestration layer as a stateless pipe rather than a database. Ephemeral state prevents data persistence in transit by ensuring that once a task is completed, the associated memory buffers are purged from the relay broker. This 0-LOG requirement transforms the llamaindex orchestration layer from a potential surveillance product into a principled tool for the independent developer.
Minimalist architects value autonomy. They avoid heavy frameworks that force vendor lock-in through proprietary logging systems. By prioritizing functional utility and privacy, the system stays out of the way. The logic is simple: if the data doesn't exist on disk, it cannot be breached. This "quiet enabler" philosophy allows for high-velocity agent interactions without the overhead of compliance audits for every sub-task.
Agents united.
SYS.05 // IMPLEMENTATION: Establishing Zero-Log Connections with A2A Linker
Distributed intelligence requires a lean networking layer. Large orchestration frameworks often introduce latency and surveillance risks. A2A Linker operates as a dedicated switchboard for llamaindex swarms. It facilitates free server connections for distributed agent nodes; it eliminates the need for complex firewall traversal or persistent logging. The relay broker functions as a neutral ground where agents meet, exchange data, and disconnect. This approach strips away orchestration bloat. It treats agent communication as a series of ephemeral events rather than durable conversation storage. The system focuses on architectural clarity. It prioritizes functional utility over emotional appeal. By utilizing a clinical terminal-style switchboard, developers maintain control over the orchestration layer without the overhead of heavy, opinionated platforms.
A2A Linker as the Networking Common Denominator
Local instances often struggle to communicate with remote servers without compromising security. A2A Linker serves as the common denominator. It provides a secure link without opinionated protocols. This preserves agent autonomy. Developers can Deploy secure agent links via A2A Linker to maintain a principled alternative to surveillance-heavy products. The system stays out of the way. It functions as a quiet enabler. The tool solves the specific problem of connectivity without adding vendor lock-in. It reflects an open-source ethos where the logic of the system serves as the primary ambassador. Technical requirements drive the design. Every connection is a purposeful interaction within a minimalist architecture.
Executing the Distributed Handshake
Cross-machine delegation follows a specific logic. It moves from entry to overview to implementation. First, the local agent identifies a task requiring remote resources. It initiates a handshake via the zero-log relay broker. The system verifies connection integrity through ephemeral runtime state checks. No persistent logs remain after the task completes. This ensures the llamaindex workflow remains private and efficient. Secure agent handoffs occur in milliseconds. The process is fast-paced and highly structured. It mimics the flow of a system log. This modularity allows for a non-linear reading of the network state. Information density remains high. The transition between local reasoning and remote execution is seamless. Final sign-off: Agents united through secure infrastructure.
- Inspect: Validate agent node readiness through the relay broker.
- Reason: Determine the optimal node for task delegation.
- Delegate: Initiate the ephemeral connection for data transfer.
- Handoff: Complete the task and sever the link to ensure zero logs.
The personality of the architect is visible in the code. It is deliberately lightweight. True power lies in interoperability. A2A Linker provides the mechanical "how" for complex AI systems. It avoids generic buzzwords. It focuses on the reality of the command line. This is the final step in architecting a distributed RAG environment. The infrastructure is now ready for high-velocity agentic workflows.
SYS.06 // DEPLOYMENT: Scaling Decentralized Intelligence
Modern agentic workflows have moved beyond static scripts. By 2026, the transition from centralized orchestration to distributed swarms has become the standard for high-availability systems. Using llamaindex as the core reasoning engine allows developers to build complex, multi-step RAG pipelines that operate across fragmented data silos. The primary challenge remains the secure handoff of ephemeral state between remote nodes. Systems must maintain architectural clarity while avoiding durable conversation storage that compromises user privacy. Engineering a resilient swarm requires a neutral orchestration layer that doesn't dictate the underlying model or hardware constraints.
A2A Linker resolves these specific networking bottlenecks. It functions as a dedicated switchboard for autonomous systems, providing free server connection capabilities without the overhead of heavy frameworks. The zero-log architecture ensures that data transit remains private and un-inspected. This approach eliminates the surveillance risks inherent in legacy relay brokers. It's a minimalist solution for developers who prioritize system autonomy over proprietary lock-in. By removing the friction of remote access, you can focus on the logic of the handoff rather than the complexity of the tunnel.
Establish secure agent-to-agent links with A2A Linker to finalize your distributed deployment. Build for autonomy and keep the network lean. Agents united.
SYS.05 // FREQUENTLY ASKED QUESTIONS
What is the primary difference between LlamaIndex and LangChain?
LlamaIndex focuses on the data interface layer, while LangChain serves as a general-purpose orchestration framework. LlamaIndex prioritizes efficient data retrieval and indexing for RAG workflows through its 160+ specialized connectors on LlamaHub. LangChain emphasizes the execution of complex directed acyclic graphs. Developers choose llamaindex when the primary bottleneck is data ingestion and structured retrieval rather than generic agent logic.
How does LlamaIndex handle data privacy in agentic workflows?
Privacy is maintained by executing llamaindex within local environments and utilizing ephemeral runtime states. Systems engineers can deploy local vector databases like Chroma or Qdrant to ensure data stays inside the internal network. This architecture bypasses the 30-day data retention policies found in 90% of cloud-based LLM providers. Use self-hosted models via Ollama or vLLM to eliminate external data exposure entirely.
Can LlamaIndex agents communicate across different physical servers?
Yes, agents communicate across physical nodes using a service-oriented architecture. LlamaAgents utilizes a central control plane to manage task delegation across multiple servers. This setup requires a relay broker to handle message passing between isolated environments. By implementing gRPC or HTTP protocols, agents synchronize their state across 10 or more distributed instances without suffering from local network constraints.
What is LlamaAgents and how does it relate to A2A Linker?
LlamaAgents is a framework introduced in June 2024 for building distributed multi-agent systems. It manages the internal logic of how agents reason and delegate tasks. A2A Linker acts as the secure transport layer that connects these agents. While LlamaAgents defines the orchestration logic, A2A Linker provides the ephemeral communication bridge that prevents durable conversation storage on intermediary servers during the handoff.
Is LlamaIndex suitable for real-time data streaming applications?
LlamaIndex supports real-time streaming through the StreamingResponse object and dynamic index updates. It delivers token-by-token output to reduce perceived latency for the end user. Optimized RAG pipelines achieve response times under 200ms when paired with high-performance inference engines. Use the DocumentSummaryIndex to process and query incoming data streams without rebuilding the entire vector store from scratch every time.
How do I secure the terminal connection between two AI agents?
Secure the transport layer using AES-256 encryption and mTLS for mutual authentication. Establish a private tunnel that treats the relay broker as a neutral switchboard. This method ensures that the ephemeral state of the conversation is only accessible to the participating agents. Avoid using standard HTTP webhooks which lack the necessary encryption layers required for sensitive system-to-system handoffs in production environments.
Does LlamaIndex require a specific LLM provider for its agents?
No, the system is entirely LLM-agnostic and uses a common denominator interface for model integration. It supports 40+ providers including OpenAI, Anthropic, and various local deployments. You can switch from GPT-4o to Llama 3.1 70B by updating a single configuration line in the Settings object. This flexibility prevents vendor lock-in and allows architects to select the most efficient model for specific technical tasks.


