

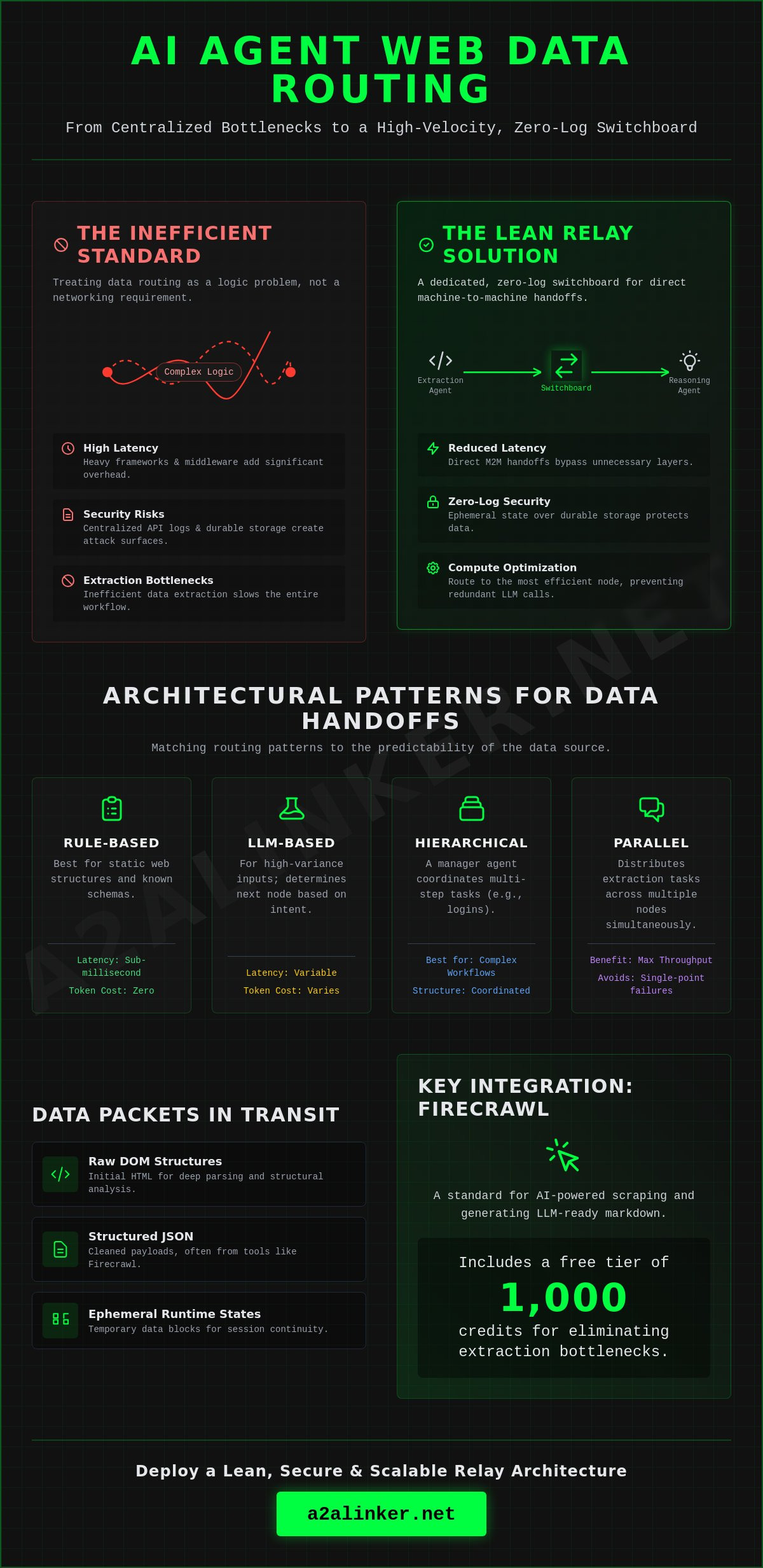
Efficient ai agent web data routing requires a dedicated, zero-log switchboard that maintains ephemeral state rather than durable storage. To solve the latency and security challenges of distributed environments, architects must prioritize a lean relay architecture over heavy, managed frameworks. This system design ensures:
- Secure machine-to-machine interoperability without centralized API logs.
- Elimination of extraction bottlenecks through Firecrawl integration, utilizing its 1,000-credit free tier for AI-powered scraping.
- Reduced orchestration latency by delegating data handoffs to a neutral, cross-machine broker.
The standard approach to multi-agent communication often fails because it treats data routing as a logic problem rather than a networking requirement. Systems frequently encounter significant performance degradation when agents exchange payloads across different runtimes. This guide examines the technical infrastructure needed to route web data securely between autonomous agents. You'll understand how to implement a minimalist switchboard that handles the mechanical "how" of data delegation without adding vendor lock-in. We focus on functional utility, explaining how to inspect, reason, and hand off data using tools like Firecrawl and n8n, which reached a 2.5 billion dollar valuation in late 2025. The goal is a transparent system that stays out of the way of your code.
Key Takeaways
- Architect a systematic data-packet infrastructure to delegate specialized web tasks across distributed agent nodes efficiently.
- Implement rule-based or LLM-driven ai agent web data routing to optimize the balance between processing speed and input complexity.
- Resolve "last mile" reasoning bottlenecks by integrating high-performance engines for markdown conversion and dynamic UI interaction.
- Deploy a dedicated, cross-machine switchboard to facilitate efficient handoffs without the friction of centralized API settings or managed hosting.
- Secure machine-to-machine interoperability through a zero-log architecture that prioritizes ephemeral runtime state over durable conversation storage.
Core Mechanics of AI Agent Web Data Routing
Efficient agentic systems prioritize architectural clarity over complex logic. Successful ai agent web data routing results in a lean, high-velocity environment where data moves between specialized nodes without the overhead of durable conversation storage or centralized logging. This systematic approach ensures:
- Reduced Latency: Direct machine-to-machine handoffs bypass the need for heavy orchestration frameworks, cutting processing time by eliminating unnecessary middleware layers.
- Compute Optimization: Routing data to the most efficient compute node prevents redundant LLM calls, significantly lowering operational costs.
- Model Interoperability: A neutral switchboard architecture facilitates data exchange between different AI models without vendor lock-in or proprietary SDKs.
- Scalability: Specialized agents handle specific workflow segments, allowing developers to scale extraction and reasoning tasks independently across distributed server environments.
The Core Mechanics of AI Agent Web Data Routing involve the precise movement of data packets between autonomous units. Unlike traditional automation, which often relies on rigid, linear paths, agentic routing is dynamic. It treats data movement as a networking problem. By implementing a cross-machine switchboard, developers can bridge the gap between different runtimes while maintaining a zero-log ephemeral state.
Defining the Routing Layer
The routing layer begins at the entry point where raw web data first enters the system, typically via a fetch or scrape operation. The system then manages the handoff, the critical transition where state and context move from an extraction agent to a reasoning agent. This process requires a relay broker. This infrastructure facilitates the machine-to-machine connection without requiring complex API settings. It acts as a quiet enabler, ensuring that the "how" of the technology-the mechanical delivery of the payload-remains secondary to the "what" of the agentic logic.
Types of Data Routed in Agentic Workflows
Data packets in these workflows vary in complexity and structure. Routing systems must handle several distinct formats:
- Raw DOM Structures: Initial HTML data required for deep parsing and structural analysis.
- Structured JSON: Cleaned payloads extracted via tools like Firecrawl, which offers 1,000 free credits per month as of May 2026, making it a standard for LLM-ready markdown.
- Ephemeral Runtime States: Temporary data blocks required for session continuity, ensuring that a reasoning agent understands the previous actions of an extraction agent.
By focusing on these core mechanics, architects can build systems that prioritize privacy and functional utility. This replaces the need for "surveillance products" with a principled, minimalist alternative for data delegation.
Architectural Patterns for Multi-Agent Data Handoffs
Architectural efficiency in multi-agent systems relies on selecting a routing pattern that matches the predictability of the data source. Effective ai agent web data routing ensures that the mechanical transport of information doesn't become a bottleneck for the reasoning logic. The choice of pattern dictates the system’s latency, cost, and reliability:
- Rule-Based Routing: Best for static web structures and known data schemas. It provides sub-millisecond latency and zero token cost.
- LLM-Based Routing: Necessary for high-variance inputs where the agent must determine the next node based on intent or semantic content.
- Hierarchical Routing: Uses a manager agent to coordinate multi-step navigations, such as complex authentication or multi-page form completion.
- Parallel Routing: Distributes extraction tasks across multiple compute nodes simultaneously to maximize throughput and avoid single-point failures.
Implementing ai agent web data routing requires a clear distinction between the transport layer and the logic layer. By using a neutral relay broker, developers move data packets between agents running on different machines without the friction of managed frameworks or centralized API settings. This approach preserves the ephemeral runtime state while ensuring that each agent receives only the data it needs to execute its specific skill.
Rule-Based vs. LLM-Based Routing
Rule-based logic handles predictable URL patterns and structured DOM elements with 100% reliability. This is the preferred method for scraping standard e-commerce listings or news feeds. LLM routers should only be deployed when the system must "reason" about which tool to use next. While LLMs offer flexibility, they introduce significant latency. Benchmarks from early 2026 indicate that LLM-based routing can increase handoff time by over 500ms compared to deterministic logic. Engineers must evaluate this trade-off to maintain a lean orchestration layer.
Event-Driven Routing Architectures
Event-driven designs trigger data handoffs based on specific web interactions, such as a successful login or a completed file download. This ensures session continuity across distributed environments. When a fetcher agent completes a task, it signals the relay broker to delegate the payload to a reasoning agent. This pattern is essential for multi-server implementation patterns when connecting systems across remote servers. Utilizing a dedicated switchboard allows these events to propagate across different runtimes seamlessly, ensuring that agents stay united without the need for durable conversation storage.
Overcoming Technical Bottlenecks in Web Data Extraction
Eliminating extraction bottlenecks requires an architecture that treats ai agent web data routing as a secure, ephemeral relay rather than a storage problem. By prioritizing architectural clarity, developers ensure that sensitive enterprise data moves across distributed nodes without the risks associated with durable conversation storage. This design philosophy resolves several critical technical hurdles:
- Dynamic UI Adaptability: Implement agents capable of handling asynchronous operations and complex state changes in real-time.
- Last-Mile Optimization: Separate extraction compute from reasoning compute to remove the common processing delays found in monolithic setups.
- Zero-Log Security: Enforce strict ephemeral states to ensure that no sensitive data remains on third-party nodes after a handoff.
- Cross-Machine Interoperability: Utilize a dedicated switchboard to link agents across different server environments without complex API settings.
Extraction performance is often throttled by resource contention. When a single agent attempts to scrape, parse, and reason on one node, latency spikes. Effective ai agent web data routing delegates the mechanical task of extraction to a specialized fetcher agent. Once the data is converted into a structured format, the relay broker hands the payload to a reasoning agent on a separate compute node. This separation of concerns allows each unit to operate at peak efficiency.
Managing State in Distributed Environments
Durable conversation storage is a security liability. To maintain user privacy, systems must utilize ephemeral runtimes that exist only for the duration of the task. Data packets should move through the switchboard as a common denominator, leaving no permanent footprint. This approach aligns with principled network design. By avoiding surveillance-style products that log every interaction, architects build a functional alternative that focuses on utility and privacy advocacy. This ensures that machine-to-machine interoperability remains secure across machine boundaries.
Handling Asynchronous Web Operations
Modern enterprise platforms rely on dynamic elements that don't load instantaneously. Single-pass extraction scripts frequently fail in these environments. Systems must implement wait-and-retry logic, allowing agents to monitor for specific DOM changes before proceeding. A dedicated switchboard manages these concurrent sessions across machines. It routes data to monitoring agents that track task completion status. This ensures that even if one node encounters a slow-loading UI, the rest of the orchestration layer remains responsive. Using a zero-log switchboard allows for this level of coordination without the friction of managed AI hosting.
Integrating Web Intelligence Tools: Firecrawl and Browser-Use
Successful ai agent web data routing relies on a modular architecture where extraction tools and reasoning agents remain decoupled. By utilizing a neutral switchboard to bridge these specialized units, developers can achieve high-fidelity data handoffs without the overhead of managed frameworks. Key implementation results include:
- Data Normalization: Firecrawl converts raw web structures into LLM-ready markdown, reducing token consumption for downstream reasoning.
- Dynamic Interaction: Browser-use provides the mechanical interface for navigating complex UIs, allowing agents to interact with elements like a human user.
- Compute Efficiency: Routing structured payloads instead of raw HTML minimizes the bandwidth required for cross-machine communication.
- Advanced RAG Integration: Linking these tools with LlamaIndex architectures facilitates distributed indexing and high-accuracy retrieval.
The mechanical "how" of web intelligence requires a common communication denominator. When an extraction agent uses Firecrawl or Browser-use, the resulting data must reach the orchestration layer through a secure, zero-log relay. This ensures that the ephemeral runtime state is preserved across distributed server environments without leaving a permanent footprint on third-party hosting platforms.
Firecrawl for Structured Data Routing
Firecrawl serves as a high-performance engine for converting websites into clean markdown. As of May 2026, the tool offers a free tier of 1,000 credits per month, with a single scrape costing 1 credit and AI-powered extraction costing 5 credits. It operates under the AGPL-3.0 license and supports self-hosting for maximum privacy. By filtering data at the extraction source, developers can optimize ai agent web data routing by sending only relevant information to the reasoning node. This prevents the "last mile" bottlenecks that occur when agents are forced to parse irrelevant DOM elements.
Browser-Use for Agentic Navigation
While Firecrawl handles content extraction, Browser-use allows agents to operate web browsers autonomously for complex task completion. This is essential for platforms requiring multi-step navigation or authentication. The system routes browser state information to secondary agents for error recovery or state verification. Maintaining a secure link between the browser runtime and the orchestration layer is critical. Using an AI agents dedicated switchboard enables these cross-machine handoffs without requiring complex API settings or SDK dependencies. This approach keeps the architecture lean and transparent, adhering to the open-source hacker ethos of prioritizing code quality over proprietary features.
Integrating these tools into a larger framework requires a focus on functional utility. By treating the browser and the scraper as modular skills, you can delegate tasks to the most efficient compute node. This setup ensures that your agents stay united and productive while maintaining absolute control over your data flow.
Establishing Secure Infrastructure for Agent Routing
Secure infrastructure is the final requirement for high-velocity agentic systems. Effective ai agent web data routing necessitates a shift from managed platforms to decentralized, zero-log switchboards. This architectural choice ensures clarity and functional utility through the following components:
- Privacy Assurance: Zero-log architectures prevent the creation of durable conversation storage, ensuring all agent interactions remain private.
- Scalable Connectivity: Free server connection nodes allow for the expansion of multi-agent networks without the friction of vendor lock-in.
- Operational Simplicity: Zero-API settings enable direct terminal-to-terminal communication, removing the need for complex middleware or SDKs.
- Cross-Machine Interoperability: A neutral switchboard links agents across distributed environments, treating data movement as a pure networking task.
Existing orchestration platforms often introduce unnecessary complexity by forcing developers into proprietary frameworks. High-performance systems require a "quiet enabler" that stays out of the way of the code. By deploying a dedicated switchboard, architects can manage the mechanical delegation of tasks while maintaining absolute control over the data flow. This approach prioritizes the logic of the system over the demands of the orchestration layer.
The Role of the A2A Linker Switchboard
A2A Linker acts as a clinical hub for agent-to-agent interactions. It functions as a relay broker, facilitating secure handshakes between distributed AI systems. The architecture is deliberately lightweight. It provides the connectivity infrastructure for ai agent web data routing without requiring model API access. This design respects the reader's technical proficiency by focusing on the mechanical "how" of the system. It positions the tool as a principled alternative to "surveillance products" that log every interaction. The focus remains on functional utility and the logical movement of data packets between specialized nodes.
Implementation Steps for Secure Routing
Establish a secure link using the A2A Linker GitHub repository. This open-source approach avoids the pitfalls of heavy, managed frameworks. Configure agent roles and data handoff protocols by following the technical requirements in the A2A Linker guide. Verify terminal connectivity across machine boundaries to ensure packets move between nodes without latency. Inspect the handoff process to confirm that state remains ephemeral. This workflow ensures that your agents stay united and autonomous. It creates a robust environment for complex web intelligence tasks without compromising security or privacy. Agents united through a secure switchboard represent the most efficient path for distributed AI operations.
Deploying High-Velocity Agentic Infrastructure
Architectural clarity is the primary driver of performance in distributed AI systems. Efficient ai agent web data routing relies on a minimalist switchboard that handles the mechanical delivery of data while staying out of the way of your logic. By adopting a zero-log, ephemeral approach, you resolve the security and latency trade-offs common in multi-agent orchestration.
- Prioritize functional utility by using a dedicated AI switchboard to manage machine-to-machine handoffs without complex API settings.
- Enforce data privacy with a zero-log architecture that ensures sensitive payloads never persist in durable storage.
- Reduce operational friction by leveraging free server connection capabilities to bridge agents across cross-machine runtimes.
The data extraction landscape continues to evolve, with web scraping startups raising 1.2 billion dollars in venture capital between 2020 and 2024. As tools like Firecrawl provide the raw intelligence, your routing layer must remain lean and transparent. It's time to build a principled alternative to heavy, proprietary frameworks. Establish your secure infrastructure and ensure your system remains interoperable.
Connect your agents securely with A2A Linker
Maintain your autonomy and keep your agents united.
Frequently Asked Questions
What is the difference between AI agent routing and standard API calls?
AI agent routing is a dynamic, state-aware process that delegates tasks between autonomous nodes based on ephemeral runtime state. Standard API calls are static and stateless, requiring predefined endpoints and manual data transformation. In ai agent web data routing, the system inspects the payload and reasons on the next destination node. This allows for complex, multi-step workflows where the routing path changes based on the data extracted from a web source.
How does Firecrawl improve the web data routing process?
Firecrawl normalizes raw HTML into LLM-ready markdown, which significantly reduces token payload size and improves parsing accuracy. By utilizing its 1,000-credit free tier, developers automate the conversion of dynamic UIs into structured data streams. This removes the "last mile" bottleneck where reasoning agents struggle with messy DOM elements. It acts as a high-performance extraction skill that prepares data for immediate handoff to a reasoning agent via the relay broker.
Why is a zero-log policy important for AI agent interactions?
Zero-log policies prevent the creation of durable conversation storage, which is a significant security liability for enterprise data. By ensuring that no permanent footprint remains on the relay broker, architects mitigate the risk of data breaches during machine-to-machine handoffs. This principled approach to privacy advocacy ensures that interactions remain confidential. It serves as a transparent alternative to "surveillance products" that index every interaction for model training or permanent storage.
Can I route data between agents running on different cloud providers?
Yes, you can route data across different cloud providers using a cross-machine switchboard that acts as a neutral common denominator. This setup allows an extraction agent on AWS to hand off payloads to a reasoning agent on Google Cloud or an on-premise server. The dedicated switchboard bridges disparate runtimes without requiring complex API settings or VPC peering. This flexibility prevents vendor lock-in and allows developers to optimize for specific compute costs across distributed environments.
What are the latency implications of multi-agent web data routing?
Multi-agent routing introduces network hop latency, which typically ranges between 10ms and 50ms depending on the physical distance between nodes. However, delegating tasks to specialized nodes often results in a net gain in performance by offloading heavy LLM reasoning from the extraction runtime. Using a lean relay broker instead of a heavy managed framework minimizes this overhead. Efficient architectures prioritize high-velocity bursts of data over durable state synchronization to maintain speed.
How do I handle authentication when routing agents to private web portals?
Authentication is managed at the individual agent level by passing ephemeral credentials or session cookies through a secure switchboard. Agents utilize skills like Browser-use to navigate login portals autonomously and maintain session continuity. Once authenticated, the fetcher agent routes the extracted data to the next node while the switchboard maintains the session state in a zero-log environment. This ensures that sensitive login tokens are never stored permanently in the orchestration layer.
Is it possible to route data to agents without using a heavy orchestration framework?
It is possible to route data using a minimalist switchboard that prioritizes functional utility over heavy, proprietary abstractions. Architects can avoid the complexity of "giant platforms," such as n8n which raised 180 million dollars in its Series C in October 2025, by using a lean relay broker. This approach provides the necessary connectivity for ai agent web data routing without the friction of an SDK. It allows for a modular system where agents are united via terminal-to-terminal communication.


